Émission sur le numérique, vie privée et algorithmes, a partir de 1:05, ici avec les invités Benjamin Bayard porte-parole de French Data Network, co-fondateur quadrature du net. et Benoît Thieulin, Fondateur et directeur de l’agence d’innovation numérique, La Netscouade.
Archives de catégorie : Articles professionnels
PHP : Industrialisation et bonnes pratiques
Note: Une version plus abouti de cet article est disponible ici.
PHP est un langage à qui on peut faire beaucoup de reproches. Cependant, sa grande popularité à permis de doter son univers d’un large panel d’outils et de pratiques permettant de l’utiliser avec efficacité.
Contrôler sa dette technique, ses temps de développement ou assurer une qualité logicielle suffisante exigent de respecter certains processus et bonne pratiques que nous allons aborder ici. Chaque thème sera accompagné d’une brève description, de ses intérêts et d’une liste d’outils non exhaustive permettant son utilisation.
Notez que la plupart des éléments de cette liste sont valables pour n’importe quel langage dès lors que ce ne sont pas des outils spécifiques à PHP.
Gestionnaire de version
 Que le développement soit effectué par une équipe ou un développeur unique, la gestion de votre code source est essentielle.
Que le développement soit effectué par une équipe ou un développeur unique, la gestion de votre code source est essentielle.
Intérêts :
- historisation de l’évolution du code
- identification des modifications apportées au code
- parallélisation des évolutions
- simplification de la gestion des versions de développement, de préproduction, etc.
Outils :
Tests automatisés
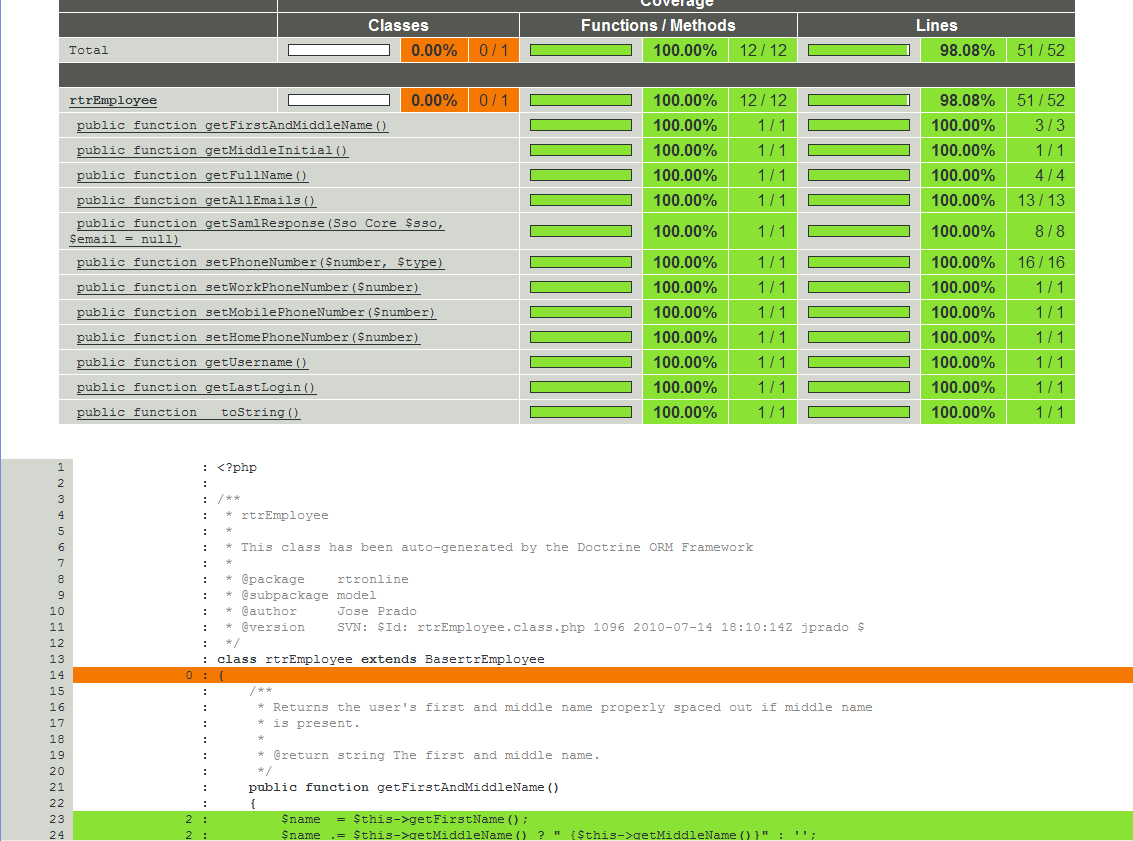 Rédiger des tests automatisés est l’unique garantie de maîtriser les régressions. Cela peut aussi être une stratégie de rédaction de spécifications fonctionnelles.
Rédiger des tests automatisés est l’unique garantie de maîtriser les régressions. Cela peut aussi être une stratégie de rédaction de spécifications fonctionnelles.
Intérêts :
- empêcher les régressions
- piloter la rédaction du code (si le développement est piloté par les tests)
- débusquer des malfaçons (si la rédaction des tests est faite après le développement)
- être au plus proche des spécifications exprimées par le client (si utilisation des tests de spécifications)
Stratégies :
- TDD : Développement piloté par les tests
- BDD : Développement piloté par le comportement
- Tests de mutations
Outils :
- PHPUnit : Tests unitaires
- Behat : Tests de spécifications
- Atoum : Tests unitaires
- Selenium : Tests fonctionnels
- PHPSpec : Tests de spécifications
- MutaTesting: Tests de mutations
Audits
 Analyser le code source permet de repérer ses points faibles : Morceaux de code complexes, non respectueux des standards, ouvrant des trous de sécurité …
Analyser le code source permet de repérer ses points faibles : Morceaux de code complexes, non respectueux des standards, ouvrant des trous de sécurité …
Intérêts :
- travailler des portions de code avant d’y être confronté dans un contexte moins propice
- connaître l’état de santé du code de son projet
Il est possible d’auditer :
- la qualité du code (code complexe, variables inutilisées, code mort, duplications, etc)
- la sécurité (injections sql, pratiques à risque, etc)
- le respects des standards
Outils :
- PHP Code Sniffer : Standards
- PHPCpd : Duplications
- PHPDepend : Complexité cyclomatique
- PHP Mess Detector : Complexité, code mort, code non optimisé, etc
- Sonar : Plate-forme d’audit et de suivi
- RATS : Sécurité
- Nikto : Sécurité
- PHP Metrics: Compléxité
- PHPloc: Taille du projet
Monitoring
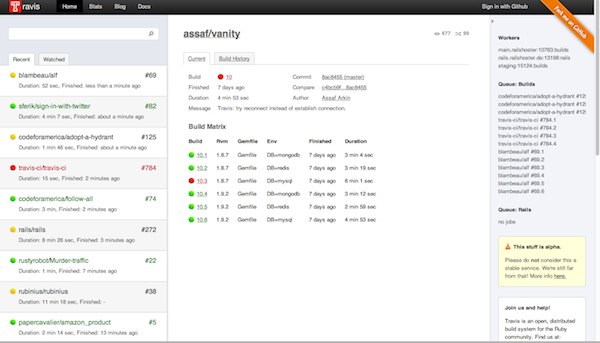 Suivre l’évolution des différentes métriques mises en place durant la vie du code source comme la réussite des tests automatisés, les différents audits , etc.
Suivre l’évolution des différentes métriques mises en place durant la vie du code source comme la réussite des tests automatisés, les différents audits , etc.
Intérêts :
- visualiser immédiatement une dégradation
Outils :
- Sonar : Plate-forme d’audit et de suivi
- Hudson : Suivis de la réussite des tests
- Jenkins: Suivis de la réussite de tests (PHP template)
- Travis-ci : Suivis de la réussite des tests
- Scrutinizer : Suivis de la qualité du code
- Siege : Temps de réponses
- Apache Bench : Temps de réponse
- etc
Profilage
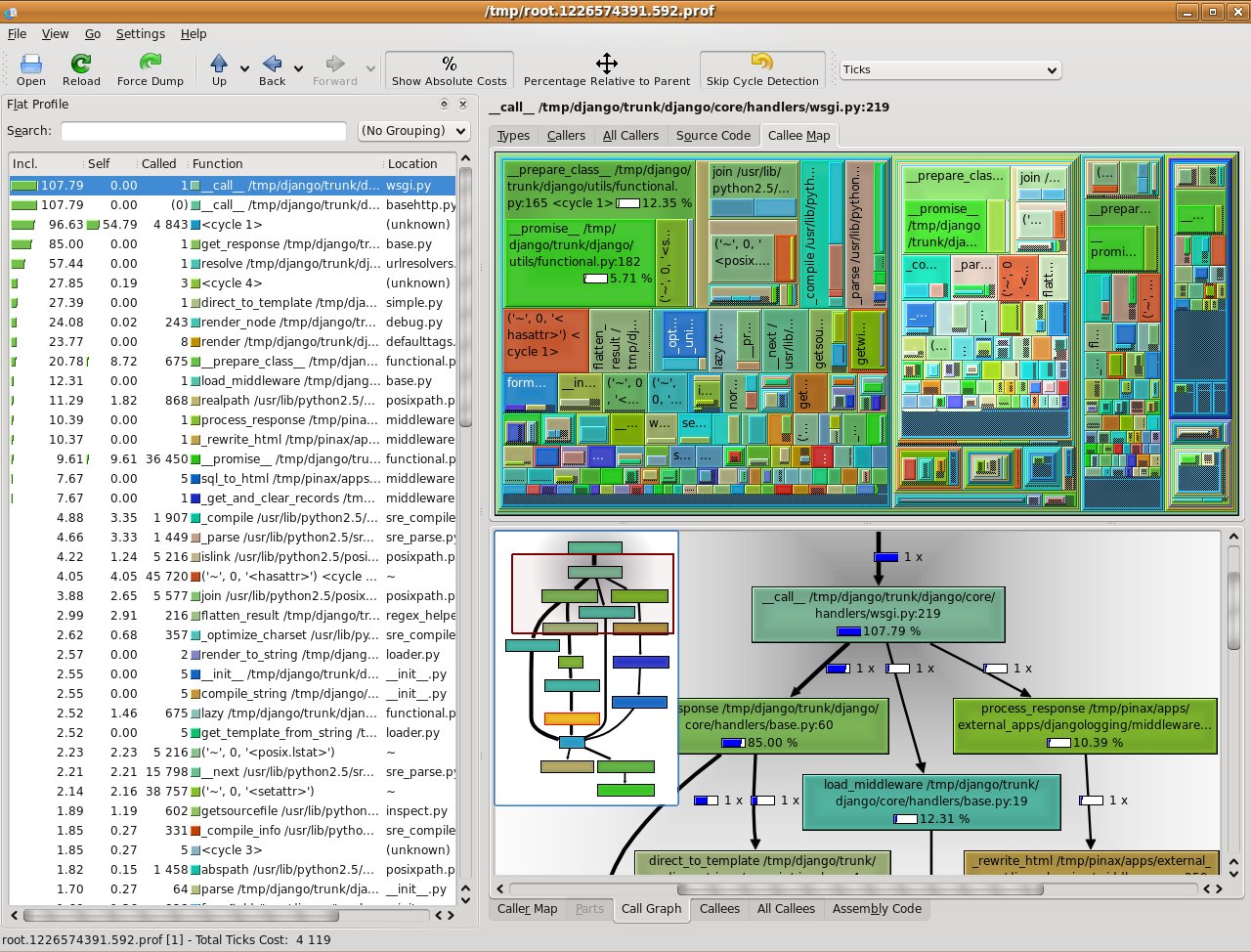 Décortiquer l’exécution du programme et repérer les goulots d’étranglements.
Décortiquer l’exécution du programme et repérer les goulots d’étranglements.
Intérêts :
- repérer les goulots d’étranglements, les fonctions à optimiser
Outils :
- xDebug: Profilage (phase de développement)
- KcacheGrind : Visualisation des profilages de xDebug
- Xhprof : (phase de production)
- Blackfire (phase et développement et de production)
Documentation
 Réduction du temps nécessaire aux développeurs pour s’approprier l’existant, maintien d’une connaissance sur la nature et l’usage du code. La documentation est une part essentielle de la conception logicielle.
Réduction du temps nécessaire aux développeurs pour s’approprier l’existant, maintien d’une connaissance sur la nature et l’usage du code. La documentation est une part essentielle de la conception logicielle.
Intérêts :
- permettre d’exploiter tout le potentiel du code (souvent du code non documenté est peu utilisé)
- ne plus consommer le temps des développeurs (qui auront déjà dû passer de temps à comprendre le rôle du code concerné s’ils n’en sont pas l’auteur)
Outils :
Gestion des dépendances
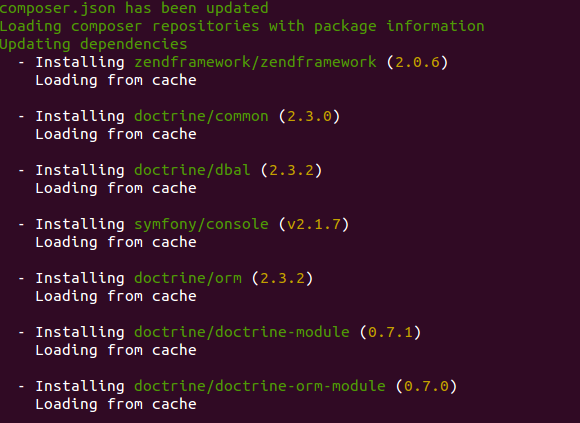 Gérer ses dépendances manuellement expose à différentes problématiques telles telles que la maintenance des mises à jour, l’inclusion des fichiers, etc.
Gérer ses dépendances manuellement expose à différentes problématiques telles telles que la maintenance des mises à jour, l’inclusion des fichiers, etc.
Intérêts :
- simplification de la gestion/installation de celles-ci
- simplification du déploiement
Outil :
Déploiement
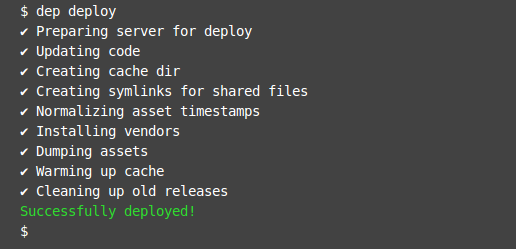 Déployer rapidement votre application/librairie c’est gagner du temps, mais aussi normaliser un processus supplémentaire. Au-delà des « scripts maison » il vous est également possible d’utiliser composer afin de créer un paquet gérable comme une dépendance.
Déployer rapidement votre application/librairie c’est gagner du temps, mais aussi normaliser un processus supplémentaire. Au-delà des « scripts maison » il vous est également possible d’utiliser composer afin de créer un paquet gérable comme une dépendance.
Intérêt :
- normalisation
- simplification
Outils :
Gestionnaire de taches
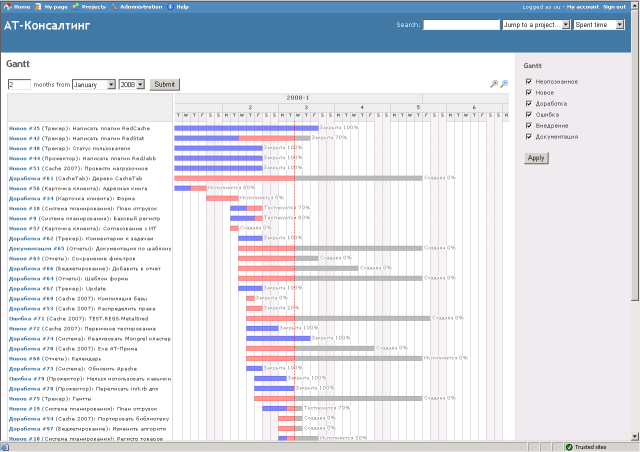 Un planning de développement est mieux maîtrisé lorsque les différentes évolutions et rapports de bugs sont listés, attribués et versionnés.
Un planning de développement est mieux maîtrisé lorsque les différentes évolutions et rapports de bugs sont listés, attribués et versionnés.
Intérêts :
- avoir une vision d’ensemble du planning
- historiser l’avancement
- faciliter l’estimation de charge
- disposer de données pour optimiser ses processus
Outils :
Standards
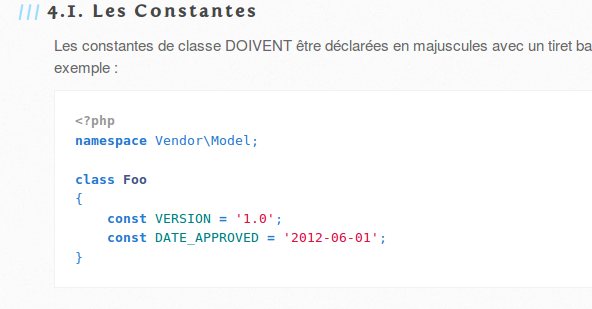 S’entendre sur des standards c’est maintenir un code plus lisible dans lequel se cacheront moins de petites erreurs.
S’entendre sur des standards c’est maintenir un code plus lisible dans lequel se cacheront moins de petites erreurs.
Intérêts :
- éviter de se réadapter systématiquement aux différents styles de code
- normalisation des espaces de noms, de l’inclusion automatique, etc.
Standards :
Performance
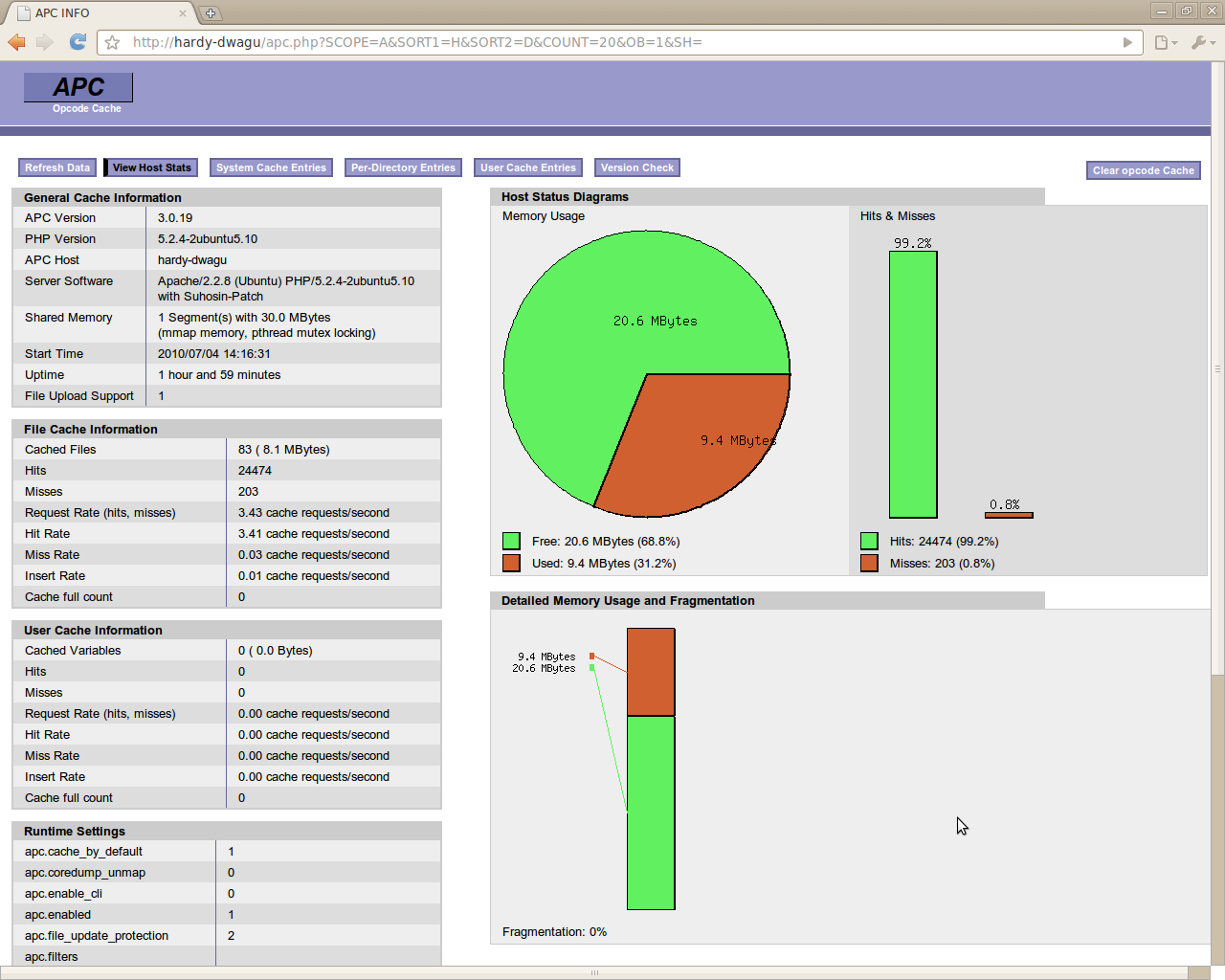 La lecture et compilation du code à chaque exécution de scripts, ou le calcul d’une réponse identique à la précédente coûte cher en ressources et temps d’exécution. Il existe naturellement des solutions pour pallier ces problématiques.
La lecture et compilation du code à chaque exécution de scripts, ou le calcul d’une réponse identique à la précédente coûte cher en ressources et temps d’exécution. Il existe naturellement des solutions pour pallier ces problématiques.
Intérêts :
- améliorer les temps de réponse
- réduire la charge serveur
Outils :
Architecture
 Les conséquences d’une mauvaise architecture se font souvent ressentir tardivement. Lorsque le code source est suffisamment avancé pour que la restructuration représente alors un coût trop élevé. Il est donc important de bien s’attarder sur ce sujet au commencement du projet.
Les conséquences d’une mauvaise architecture se font souvent ressentir tardivement. Lorsque le code source est suffisamment avancé pour que la restructuration représente alors un coût trop élevé. Il est donc important de bien s’attarder sur ce sujet au commencement du projet.
Les frameworks sont d’une aide extrêmement précieuse concernant ce point bien que l’on puisse nous-mêmes construire une architecture et implémenter des patrons de conceptions.
Intérêts :
- réduire la charge que représente l’introduction de développeurs à votre projet
- adopter une architecture c’est éviter d’en expérimenter une
- forme vos développeurs à de bonne pratiques
- gains de temps
- robustesse
- maintenabilité
- sécurité
Frameworks :
Principes:
Exemple:
- DesignPatternsPHP: Exemples d’implémentations
Intelligine : Simulateur d’intelligence collective
Voilà maintenant quelques années que j’ai entamé le projet de créer un simulateur d’intelligence collective. Plus précisément d’insectes sociaux tels que les fourmis, les termites ou encore les abeilles1.
Ce projet commence désormais à être assez avancé pour en faire une présentation et peut-être susciter l’intérêt de personnes souhaitant y participer.
Les insectes sociaux ?
Les colonies d’insectes sociaux sont des systèmes extrêmement complexe et évoluées. Il est commun de penser que seul les êtres Humains pratiquent l’élevage et l’agriculture. Il n’en n’est rien. Les fourmis pratique l’élevage de pucerons 2 et la culture de champignons3. Les termites pratiquent eux aussi la culture de champignons4.
 Les termites parviennent à pratiquer cette agriculture sous le soleil Africain. Leur forteresses peuvent être composées de galeries atteignant 70 mètre de profondeur, puisant la fraîcheur des nappes phréatiques. Cela afin que, par un système complexe d’aérations digne d’un architecte en thermodynamique, la zone de culture des champignons soit maintenue à 27°C. Alors que la température extérieure dépasse généralement les 35°C5.
Les termites parviennent à pratiquer cette agriculture sous le soleil Africain. Leur forteresses peuvent être composées de galeries atteignant 70 mètre de profondeur, puisant la fraîcheur des nappes phréatiques. Cela afin que, par un système complexe d’aérations digne d’un architecte en thermodynamique, la zone de culture des champignons soit maintenue à 27°C. Alors que la température extérieure dépasse généralement les 35°C5.
Cependant les individus qui composent ces sociétés ne jouent chacun qu’un rôle limité et guidé par leur instinct. Une idée reçu voudrait que ce soit la ou les reines qui dirige la colonie. Ordonnant ou oriantant le comportement de ses sujets. Mais la non plus il n’en n’est rien 6. Le fonctionnement d’une colonie est le résultat d’un merveilleux comportement d’intelligence collective. Une collaboration où chaque individus ne possède qu’une vision limité de son environnement.
Pour citer Wikipédia à propos de l’intelligence collective:
« La connaissance des membres de la communauté est limitée à une perception partielle de l’environnement, ils n’ont pas conscience de la totalité des éléments qui influencent le groupe. Des agents au comportement très simple peuvent ainsi accomplir des tâches apparemment très complexes grâce à un mécanisme fondamental appelé synergie ou stigmergie »
Quel lien avec l’algorithmique?
Si nous devions simplifier le fonctionnement de ces sociétés nous pourrions dire qu’elles sont l’effet de la répétition de l’action de chaque individus qui la compose. Individus, qui, inlassablement effectues leur petites tâches durant toute leur existence.
Il s’avère que nos processeurs et langages informatique sont tout à fait adapté lorsqu’il s’agit de répéter l’exécution de modèles définis. On peux donc imaginer construire une colonie virtuelle sur ces modèles.
Déjà aujourd’hui la nature (et les insectes sociaux) inspire des modèles informatique. Algorithmes génétiques, Algorithmes de colonies de fourmis, etc. Et avouons le, en tant que concepteur logiciel, les insectes sociaux sont une parfaite inspiration lorsqu’il s’agit d’intelligence artificielle !
Le projet intelligine
Le projet intelligine n’a pas pour but de révolutionner les Métaheuristique ou les algorithme de colonies de fourmis mais simplement de tenter de créer une société virtuelle capable de s’auto-organiser et de s’adapter à une environnement évolutif. Tout en s’inspirant du comportement d’insectes réels.
Bien sur, cela dans une moindre mesure. Premièrement, il est difficile de rivaliser avec des millions d’années dévolutions. Deuxièmement, ce que nous appelons un comportement « simple » de la part d’un individu reste tout de même extrêmement difficile à interpréter avec certitude.
En quoi ça consiste ?
Algorithmiquement
La réalisation du logiciel doit s’accompagner de restrictions. Dans la nature, les individus n’ont qu’un accès limité à leur environnement. Les algorithmes représentant les individus et permettant leur prise de décision doivent donc se cantonner à ne pouvoir lire qu’une partie des données de l’environnement.
Un effort de malléabilité doit être effectué sur l’organisation des différentes briques du logiciel. De manière à pouvoir modifier, remplacer et retirer des parties de code en fonction de l’évolution de nos connaissances à propos de ces insectes.
Entomologie

Il faut faire confiance à la nature. Il n’y as pas meilleur architecte que la sélection naturelle pour façonner des comportements optimisés. D’autant que les espèces qui nous intéressent sont extrêmement anciennes. Il faut donc comprendre ces mécanismes au lieu d’en inventer de nouveaux.
Une grande partie du travail concerne alors l’étude des insectes sociaux: Consulter le résultat des travaux déjà réalisés, interroger des spécialistes, des passionnés, mener des expériences … Cela afin d’écrire des algorithmes aussi proche que possible de leurs inspiration naturelles.
Première version: SimTermites
La première réalisation concrète de ce grand projet à été le programme « SimTermites« . Ce fût l’occasion de me confronter concrètement à différents aspects d’un tel projet:
- Les performances jouent un grand rôle. Simuler le comportement de milliers d’individus au sein d’un environnement déterminant dans leurs action nécessite beaucoup de calculs !
- L’organisation du programme. Une simulation de la sorte atteint rapidement un niveau de complexité effrayant. Ce qui oblige à être très attentif à la manière d’organiser le code source de l’application et à respecter des principes robustes et éprouvés 7.

Ces différents aspect étant devenus évident pendant la réalisation de ce programme il sembla alors nécessaire de reprendre le programme depuis le début.
Car si vous êtes néophyte de la conception logicielle, un programme est composés de millions d’instructions (tel qu’un très longue recette de cuisine). Où chaque morceau qui la compose est reliés à d’autres. Il est donc très difficile de modifier profondément un logiciel. C’est pourquoi il est vital que durant sa réalisation des précautions soit prisent pour le rédiger correctement. Autrement sa modification, son évolution ou corrections devient extrêmement chronophage.
J’ai donc décidé que SimTermites resterait ce qu’il est. Et qu’un nouveau chantier devait commencer.
Synergine + Intelligine
J’ai donc commencé par réaliser un framework 8 dédié à la réalisation de programmes dont la nature serait de faire évoluer des entités indépendantes (représentées par des algorithmes) au sein d’un environnement. Ensuite, développer le logiciel censé prendre la relève de SimTermites.
Aujourd’hui, l’un et l’autre sont développé. Le framework: Synergine, suffisamment stable pour l’utiliser. Le simulateur d’intelligence collective: Intelligine, jeune mais assez avancé pour commencer le travail sur les aspects comportementaux des individus.

Intelligine: Quelques visuels de la version courante
Note: Le framework Synergine permet de créer la sortie graphique que l’on souhaite indépendamment du programme. Les visuels ci-dessous ne sont qu’une implémentation « rapide » que j’ai réalisé moi-même pou les besoins du développement.
Déplacement d’œufs

Récupération de ressources

Et maintenant ?
Différentes étapes sont encore à franchir avant d’atteindre une version stable est plus convenable du simulateur. La liste est établis dans le tracker9 du projet disponible ici:
http://work.bux.fr/projects/intelligine/issues
De nombreux questions restent encore à éclaircir et à débattre sur le comportement des insectes sociaux et leur équivalent algorithmique. Quelques débat sont déjà ouvert par ici:
http://work.bux.fr/projects/intelligine/boards.
Si vous êtes développeur, myrmécologue, intéressé par les insectes, l’intelligence artificielle ou simplement pris d’enthousiasme pour le projet, nous serions heureux de collaborer avec vous ! Il y a beaucoup de choses qui peuvent être faite: Faire des recherches, documenter, partager ses connaissances, concevoir le programme …
Les différentes adresses intéressantes:
- Forum de discussion (comportement des insectes, algorithmique, …): http://work.bux.fr/projects/intelligine/boards
- Développements prévus: http://work.bux.fr/projects/intelligine/roadmap
- Code source du simulateur: https://github.com/buxx/intelligine
- Code source du framework: https://github.com/buxx/synergine
- D’autres projets similaires: http://work.bux.fr/projects/intelligine/wiki/Autre_projets_similaires